Phantom WebSocket close events

One of the reasons for the mysterious websocket close code=1006 reason="" error at the server end.
Putting this here for search engines to find it in case anyone else hits it...
Deployed a new service to a GCP compute node recently. Works perfectly in development, but the server sees a WebSocket close after exactly 60s in production.
The application is a bit strange in that, after the initial open, all the Websocket traffic is one way (server -> client status updates). Often the cause of WebSocket issues is an underlying network component prematurely terminating the connection when it sees no traffic so I was ready to blame the GCP infrastructure (firewalls etc). That can't be the issue here as the closes were occurring even though the socket was active and sending status updates to the client which is usually enough to keep TCP sessions open.
Turns out it was an nginx config that I had forgotten was there. Nginx supports proxying websockets, and I was using this for the service. It's default read/write timeouts are just 60s, and that is at a data level, not a TCP connection level. If the socket is quiescent for longer than this then the proxy closes the connection.
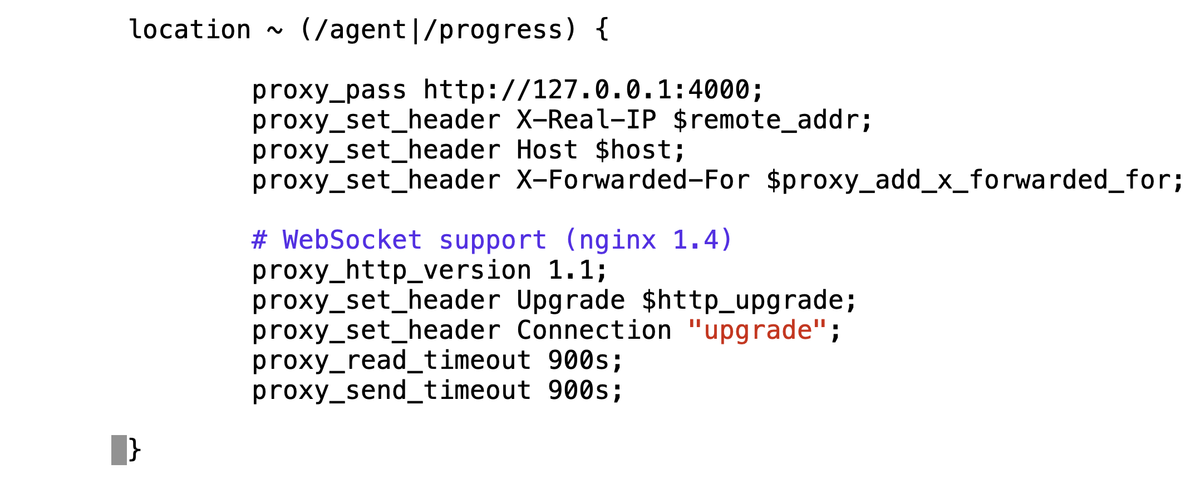
The fix is to add proxy_read and _send timeouts to the nginx config:
# WebSocket support (nginx 1.4)
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_read_timeout 900s;
proxy_send_timeout 900s;
The last two lines above fix my problem, as I actually want sessions that are dormant for more than 15-mins to get dropped. I have seen recipes that suggest setting this to 86400s (1 day), but I would be cautious as that may cause significant resource leaks if you have karge numbers of quiescent clients. YMMV.